Aš tikriausiai jau įgrisau jums su savo rinkiminėm schemom. Bet va vieną dar sugalvojau čia įdėti. Vėliau mėginsiu ką nors dvasingesnio parašyti. Gal net kas gausis.
O čia dabar bus mano paties sugalvotas ir jau beveik standartizuotas metodas, parodantis pokyčių Seimo rinkimų sąraše mastą. O tas mastas, savo ruožtu, galbūt atsitiktinai visai koreliuoja su galutiniais rinkimų rezultatais.
O rinkiminis sąrašas, žinia, yra viena karščiausių temų partijos viduje ir taip pat gan gausiai aptarinėjama viešojoje erdvėje. Gerą sąrašą sudaryti nelengva: jis gan svarbus rinkėjams, todėl partija turi suprasti ką rinkėjai galvoja; sąrašas tai pat svarbus kandidatams, todėl jie daro tokią savotišką rinkiminę kampaniją partijos viduje. Tos vidinės kampanijos būna įvairios: nuo kokių nors straipsnių rašymo vidiniuose portaluose ar emeilų siuntinėjimo iki visokių intrigų schemų kūrimo. Suvaldyti visą šį procesą tikrai nelengva.
Tad rodiklis gautas mano metodu gali padėti suvaldyti tą procesą, nes jis gan racionalus ir lengvai pamatuojamas. Tiesa, politikai visada ras dėl ko pasiginčyti, net ir dėl to, kad 2×2=4.
Mano rodiklis parodo kiek geras partijos rinkiminis sąrašas pagal tai kiek pokyčių jame įvyko po rinkėjų reitingavimo: kuo pokyčių daugiau – tuo rodiklis prastesnis.
Viskas prasidėjo nuo šios schemos. Aš ten skaičiavau-skaičiavau, normalizuot visaip bandžiau ir dar ten kažką dariau, ko nebe atsimenu, nes excelį tą kažkur pamečiau. O man ten taip viskas sudėtingai gavosi vien dėl to, kad aš mėginau matematiškai įvertinti aukštai sąraše esančių kandidatų judėjimą taip, kad jis būtų palyginamas su žemai sąraše esančiais judėjimais.
Išganinga mintis buvo remtis reitingų skaičiais, bet tada reikėjo sugalvoti metodą. Kažkas keisto gavosi kitoje schemoje.
Na, o rezultatu vėliausioje schemoje esu galų gale patenkintas. Viskas buvo padaryta kiek paprasčiau, nei mėginau iki šiol: nebeskaičiavau kažkokių keistų koeficientų, o tiesiog panaudojau tuos pačius reitingus kaip rodiklį.
Vėliau tą savo metodą ir rezultatus pristačiau partijos Vilniaus skyriaus rinkimų rezultatų aptarime ir susilaukiau palankių vertinimų (bent jau iki šiol man taip atrodo). Tiesa, kiek anksčiau feisbuke gavau velnių iš kitų partijos skyrių dėl retorikos, t.y. užtai, kad parašiau, jog partija kažkuriuos kandidatus pervertino. Aš specialiai rinkausi aštresnius žodžius, kad užkabintų. Tai užkabino.
Savo prezentacijoje Vilniaus skyriui parodžiau kaip suskaičiavau tuos kandidatų pokyčių rodiklius, tad įdedu jį į čia. Jis turėtų padėti suprasti visą metodo esmę:
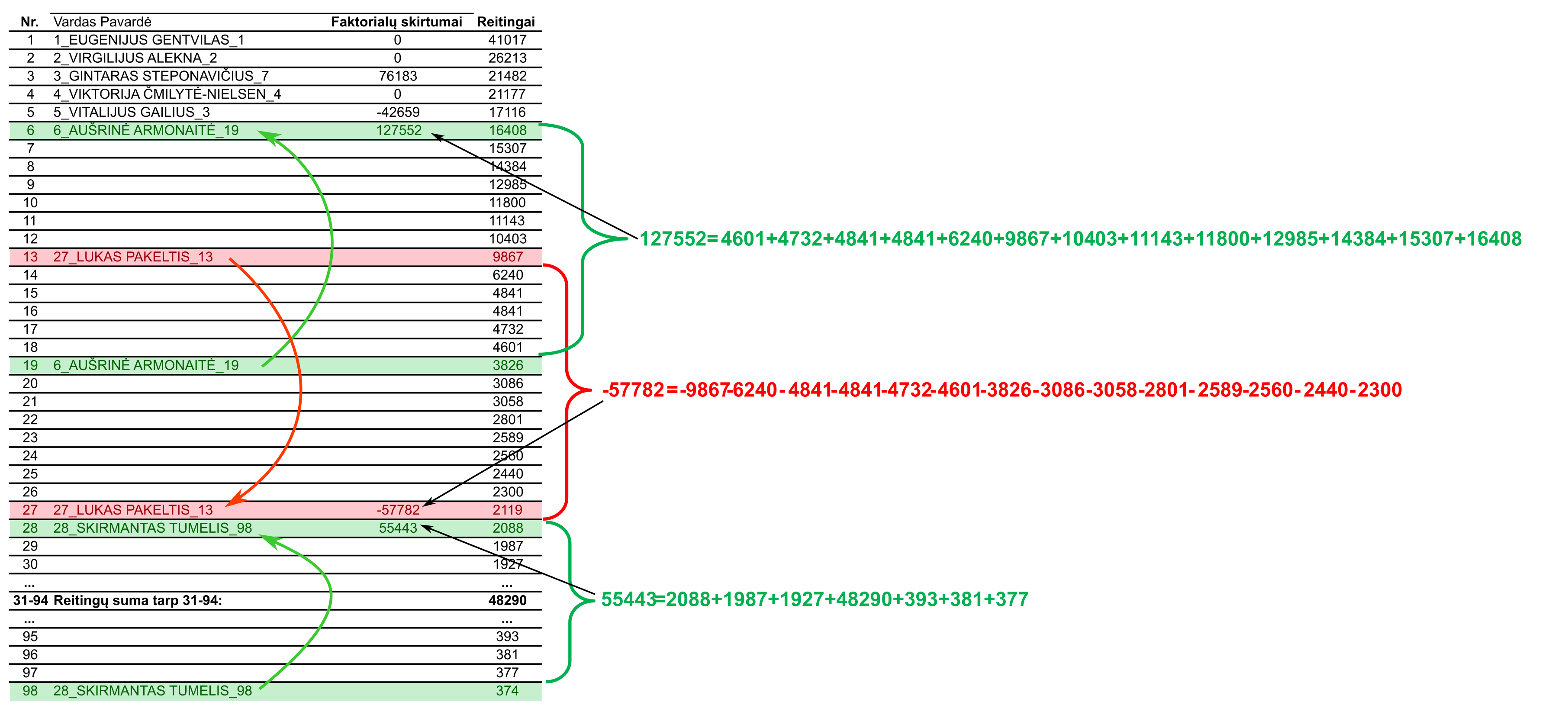
Na, o paskui, norėdamas gauti skaičių, kuris galėtų būti palyginamas su kitomis partijomis arba kitais rinkimais, padariau šiuos skaičiavimus:
- Susumavau visus visų kandidatų reitingus nuo didžiausio iki mažiausio: t.y. ties Eugenijum Gentvilu – visų kandidatų gautų reitingų suma. Ties Virgilijum visų kandidatų reitingų suma išskyrus Eugenijaus ir t.t.
- Susumavau visas tas aukščiau gautas sumas ir gavau skaičių, kurį padalinau iš visų kandidatų pokyčių reitingų sumos.
- Kandidatų pokyčių reitingų sumą dar padalinau iš dviejų, nes pakilimų suma lygi nukritimų sumai; juk sistema uždara – kiekvienas pakilimas lemia dalį nukritimų per tiek pat reitingų.
- Gautą skaičių dar apdorojau taip, kad jis taptų procentais, kur 100 procentų reiškia, jog pasikeitimų sąraše nebuvo, o kuo mažesni procentai – tuo daugiau buvo pasikeitimų; tie skaičiavimai tokie: [2 žingsnio sumų suma]/([2 žingsnio sumų suma]-[2 žingsnio visų kandidatų pokyčių reitingų suma]/2); tada dar gautu skaičiumi padalinau vienetą ir padauginau iš 100. Excelyje tai atrodo paprasčiau: E1=SUM(A:A)/(SUM(A:A)-SUM(B:B)/2); F1=1/E2*100, kur F1 ir yra tas mano rodiklis.
Ir štai rezultatas:
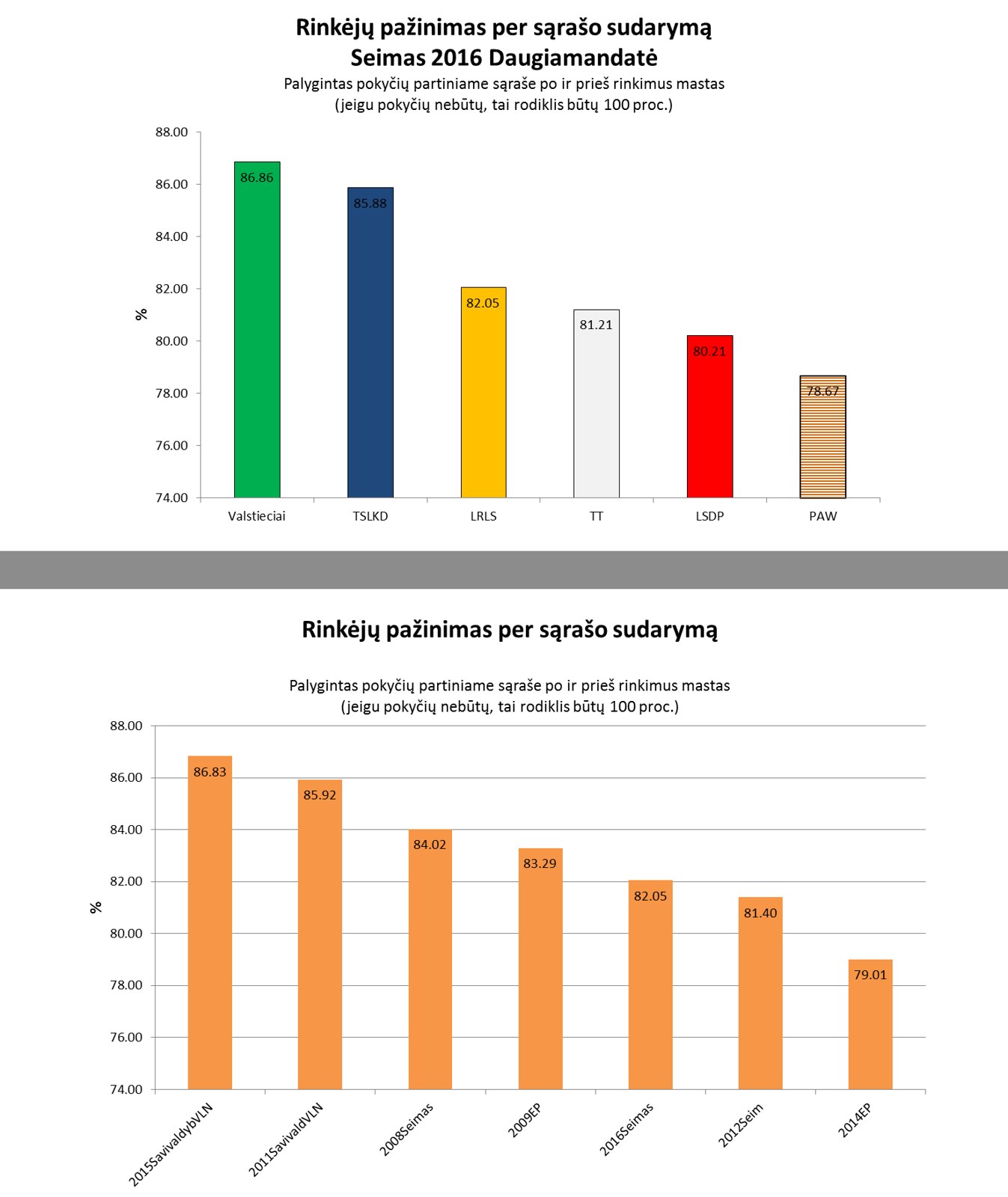
Štai čia mano minėtos koreliacijos: Valstiečiai pirmi, toliau konservatoriai, tada LRLS. Iš konteksto iškrenta socdemai. Pagal mano rodiklį jų sąrašas blogesnis už LRLS, nors sumoje gavo daugiau balsų.
Valstiečiai tokį rezultatą gavo galimai dėl to, kad jiems nereikėjo labai stengtis sudaryti savo sąrašo (bent jau aukščiau 5uko), nes nelabai juos kas žino, o balsavo, žinia už permainas. Konservatorių galimai irgi rinkėjai specifiniai, kurių dalis manau pasitiki vien tuo, kad yra konservatoriai ir reitinguoja tuos, ką siūlo partija, bet bent jau per šiuos rinkimus, bent jau feisbuke buvo daug ažiotažo reitinguoti naująją kartą, o ne talibaninę. Atsakymų ir tuo pačiu klausimų gautumėm daugiau, jei pasinagrinėtumėm konservus praėjusių rinkimų perspektyvoje. Gal ir pasidarysiu tai kada nors, jei bus pakankamai daug laĩkų šiam mano postui.
Metodo silpnosios pusės yra tos, kad labai daug rinkėjų reitinguoja pirmuosius sąraše. Taip pat pastebimos tendencijos reitinguoti paskutinius. Dabar tai ne tik žinoma visiems tiesa, bet ir mano galva itin gero duomenų analitiko patvirtintas faktas. Tai, kad žmonės linkę reitinguoti tai ką siūlo partija mano metodą susilpnina tuo, jog partija turinti gavusi daugiau balsų – gaus ir geresnį rodiklį, nes paprasčiausiai daugiau žmonių reitinguos pirmąjį penketuką. Beje tas pats Jonas Bačelis taip pat parodė, jog didžioji dalis rinkėjų išvis nesivargina ko nors reitinguoti, o tai šį metodą taip pat susilpnina. Galbūt vertėtų pirmojo penketuko į skaičiavimus išvis neįtraukti. Reiks pamėginti ir taip paskaičiuoti kada nors.
Silpnų vietų yra ir kitur: skirtingų partijų rinkėjai gali skirtis pakankamai daug, t.y. tiek, kad šio metodo gautų rodiklių sulyginimas nebūtų toks prasmingas. Bet ši prielaida irgi labai sąlyginė.
Galima taip pat kabinėtis ir prie grafikų pavadinimų. Nes priežasčių ir pasekmių ryšys čia nebūtinai būtent toks. T.y. jeigu partijos sąrašo sudarytojai, kokiu nors būdu nukeliautų ateitin ir grįžę padarytų tokį sąrašą, koks bus po rinkimų – jis gali vis vien keistis, nes kandidatams vieta irgi itn svarbi ir jų motyvacija daryti geresnę kampaniją gali būti didesnė, o kai neapsisprendusių rinkėjų daug – tai gali būti reikšminga.
Bet vėlgi – kuo mažiau pokyčių sąraše – tuo geriau. Tai sako, kad partija pažįsta ir savo rinkėjus ir savo kandidatus – o tai būtų labai gera partijos savybė.
Tai tiek šiam kartui.
Dar žiūrėkite mano praėjusias schemas:
Schema #42
Schema #41
Schema #40
Schema #39
Schema #38
